
RDNA 4 Architecture
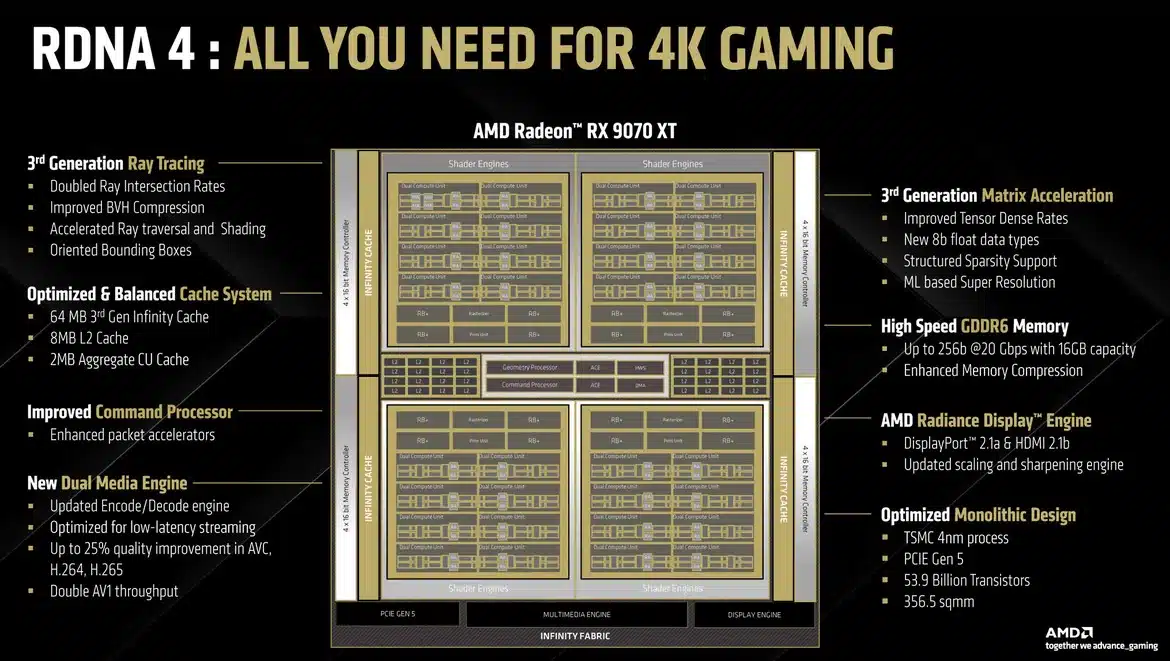
The Navi 48 GPU has 64 CUs utilized by four shader engines. Each CU contains 64x stream processors, so the GPU has 4096 stream processors in total. All 64x CUs are enabled in the 9070 XT, while the RX 9070 has only 56x enabled. In short, the 9070 XT has 4096 stream processors, 128 AI accelerators, 64 RT accelerators, 256 TMUs, and 128 ROPs. The GPU also has 16 GB of 20.1 Gbps VRAM running on a 256-bit wide GDDR6 interface and 64 MB of 3rd Gen Infinity Cache.
According to AMD, the RDNA 4 compute unit includes many enhancements for improved gaming performance per CU, significant generational uplifts in ray tracing and AI acceleration, boost clocks approaching 3GHz, improved streaming/recording quality in the new media engine, and support for all the latest technologies to keep the Radeon RX 9070 series-powered systems going for the years to come.
Within each CU, updated 3rd generation Ray Accelerators offer double the peak throughput of RDNA 3. Moreover, in RDNA 4, the Ray Accelerators offer double the ray intersection rates, improved BVH compression, accelerated ray traversal and shading, and additional support for a new feature called Oriented Bounding Boxes. 3rd Generation Matrix Accelerators offer improved performance, support for 8-bit float data types, and structured sparsity support.
AMD RDNA 4 Compute Units

AMD states that the fundamental workloads for any GPU are general raster and compute operations. AMD’s engineers predict that these types of GPU loads will continue to dominate in the future, even with the emergence of new rendering techniques. In other words, AMD doesn’t seem to embrace NV’s optimism for AI frames but prefers to focus more on actual GPU horsepower, which concerns raster performance. I couldn’t agree more with AMD on this!
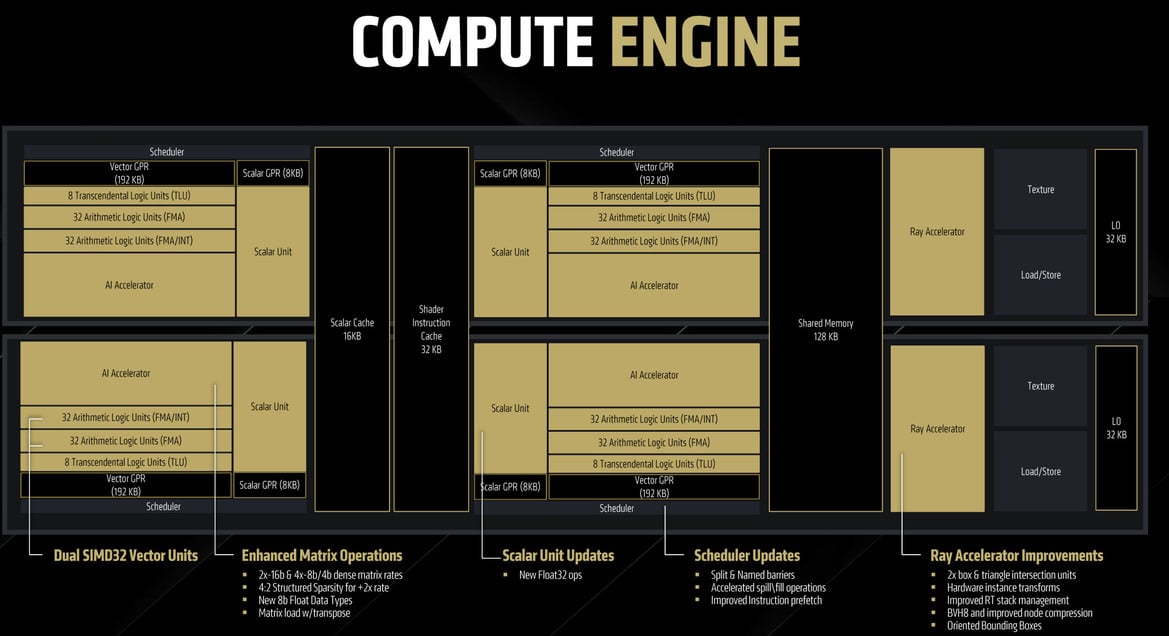
The new AMD RDNA 4 compute unit features an enhanced memory subsystem, improved scalar units, dynamic register allocation, increased efficiency per CU, and much higher clock speeds than RDNA 3. These enhancements significantly improve gaming performance per CU, allowing Radeon RX 9070 Series graphics to provide performance comparable to our previous generation RX 7900 Series despite the lower total CU count.
The GPU uses 2MB of CU cache, 8MB of L2, and 64MB of Infinity Cache (3D generation), installed between the shader engines and the memory controllers. The GPU also has 16GB of GDDR6 memory, operating at 20.1 Gbps over a 256-bit width interface. Lastly, the memory controllers utilize memory compression techniques for faster data transfers.
Each CU has two scheduler blocks, driving a 192 KB general-purpose register (GPR), an 8 KB scalar GPR, 32 FMA ALUs, and 32 FMA+INT ALUs. There are also eight transcendental logic units. In RDNA 4, we saw the introduction of a new concept with a pair of SIMD32 vector units for even more parallelism. The Scalar Unit comes with support for newer Float32 ops. Schedulers are updated with accelerated spill/fill operations. Instruction prefetching is improved. The latest generation AI Accelerator comes with two 16-bit and four 8-bit/4-bit dense matrix compute rates, support for 4:2 structured sparsity for doubling throughput, and matrix loads with transpose. Lastly, AMD has incorporated many technologies from its CDNA 3 Radeon Instinct AI ML accelerators on the AI Accelerators of RDNA 4, including enhanced and power-optimized WMMA, improvements to the ops per CU, support for FP8, E4M3 and E5M2 formats, and 4:2 structured sparsity.
3rd Generation Raytracing Accelerators
 |
 |
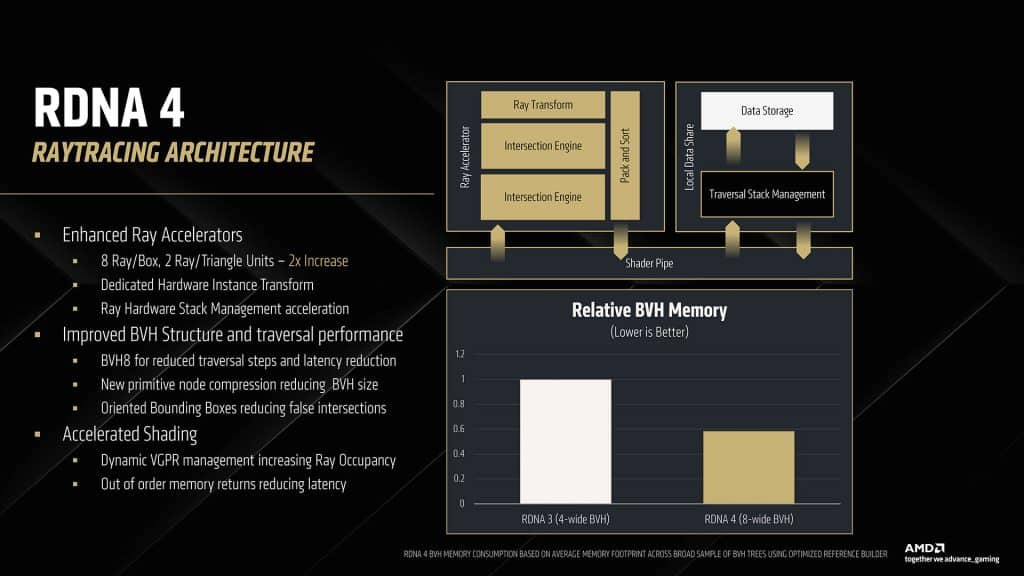
With ray tracing becoming more widely adopted by game developers and, at times, required to play the latest titles, gamers with older GPUs need to upgrade if they want to follow up, meaning a notable investment since capable GPUs with enhanced RT performance belonged to Nvidia’s lines mostly so far, leaving them with reduced options. Hopefully, this will change now with RDNA 4, AMD’s 3rd generation RT Accelerators, since, according to its maker, it received upgrades that result in 2x the ray traversal capabilities of RDNA 3. These include adding a second ray intersection engine and optimizations to effectively reduce the overhead needed to execute raytracing calculations.

A key component of ray tracing workloads is constructing a Bounding Volume Hierarchy (BVH) data structure, which defines the geometric data properties of the image. One key improvement to highlight in the RDNA 4 RT Accelerator is an innovative approach to handling BVH called “Oriented Bounding Boxes,” which reduces the size and complexity of the BVH data. These changes deliver much more efficient ray traversal through the geometry and with a lower memory cost, making better use of available VRAM capacity and bandwidth.
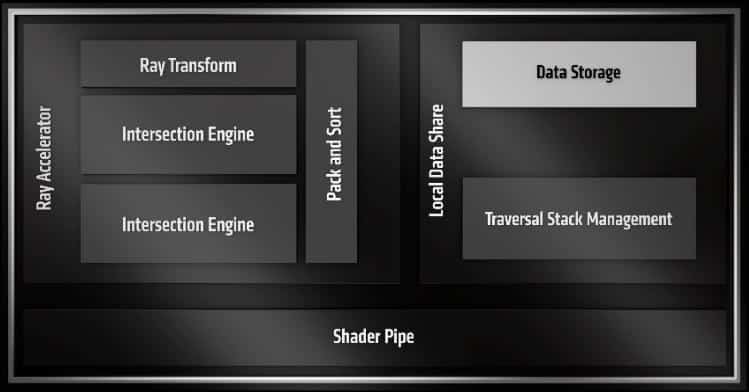
AMD added a second intersection engine within the RT Accelerator, doubling the performance for both Ray/Box and Ray/Triangle testing. Based on our analysis of raytracing workloads, we also created a dedicated ray transform block, which increases the hardware’s performance as rays are traversed into the lower levels of the BVH tree.
Out-of-Order Memory
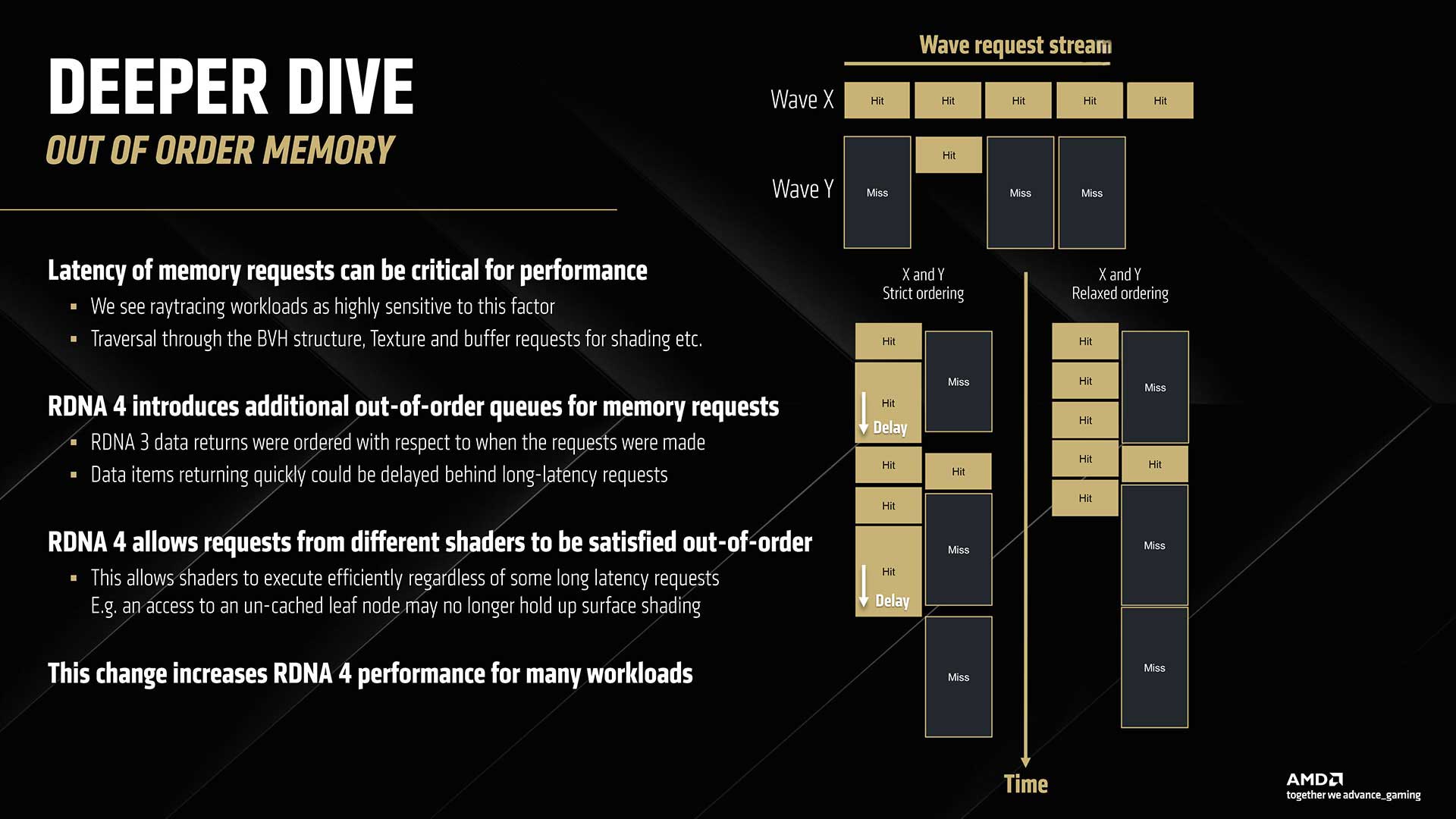
Ray tracing and ML acceleration are memory-sensitive applications, so AMD had to change its memory management system by introducing new out-of-order memory. All math is executed in waves on an RDNA GPU, and mutual dependencies between waves can cause memory request stream misses, as one wave’s memory request queue waits for the other wave to complete its task. This is solved with a new out-of-order (relaxed ordering) memory management.
Dynamic Registers
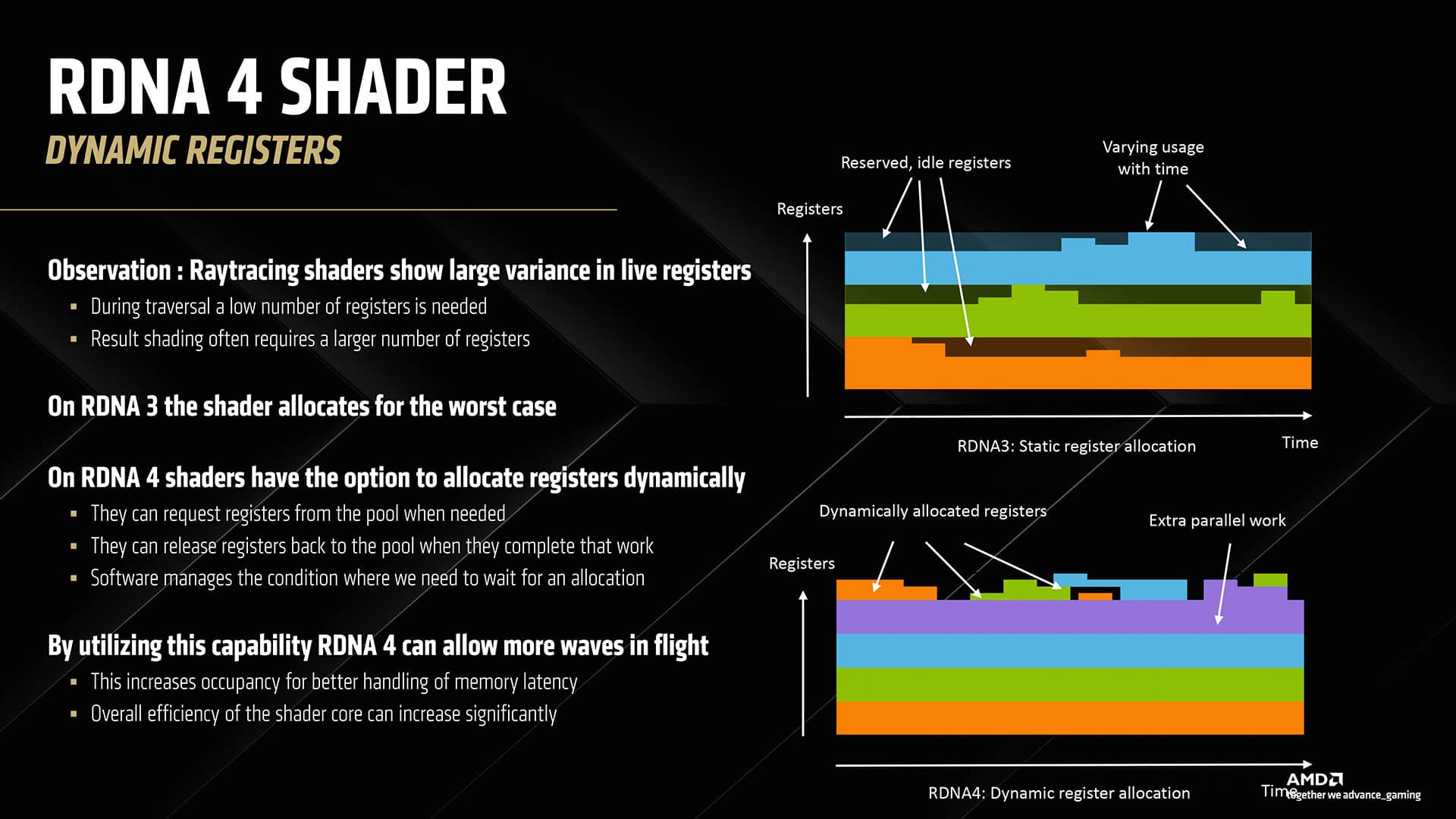
Still, on the AMD cards, a fairly big chunk of the ray tracing stack is executed on shaders. However, AMD has made advances to ensure the cost of ray tracing on the GPU’s shader resources is minimal, with the introduction of Dynamic Registers to improve parallelism.
2nd Generation AI Accelerators

The new AI Accelerators utilize two 16-bit and four 8-bit/4-bit dense matrix compute rates, support 4:2 structured sparsity for doubling throughput, and matrix loads with transpose.
RDNA 4 includes 2nd generation AI Accelerators, which offer the latest AI-accelerated experiences for gaming, content creation, and generative AI. According to AMD, the enhancements to AI acceleration in AMD RDNA 4 can efficiently process advanced AI models much faster than was possible with previous generations of hardware through a combination of adding more math pipelines for AI calculations, expanding the capabilities of the AI Accelerator to support new data types such as FP8, and support for inference optimization techniques such as structured sparsity. These changes deliver the most significant generational uplift in AI performance we have brought to an architecture designed for gaming graphics.

Enhanced Media Engine
The Media Engine optimizations have focused on improving the encoding quality when recording and streaming across all major codecs, such as H.264, HEVC, and AV1. When using the H.264 encoder at 6000 Kbps, a popular format for game streaming, the updates to the media engine can result in significant image quality improvements, as shown below. Since image quality is an inherently subjective topic, we encourage you to test a variety of scenes to evaluate the encoding performance and quality differences between RDNA 3 and RDNA 4.
 |
 |
RDNA 4 Video Codec Support

AMD FidelityFX™ Super Resolution 4 (FSR 4)
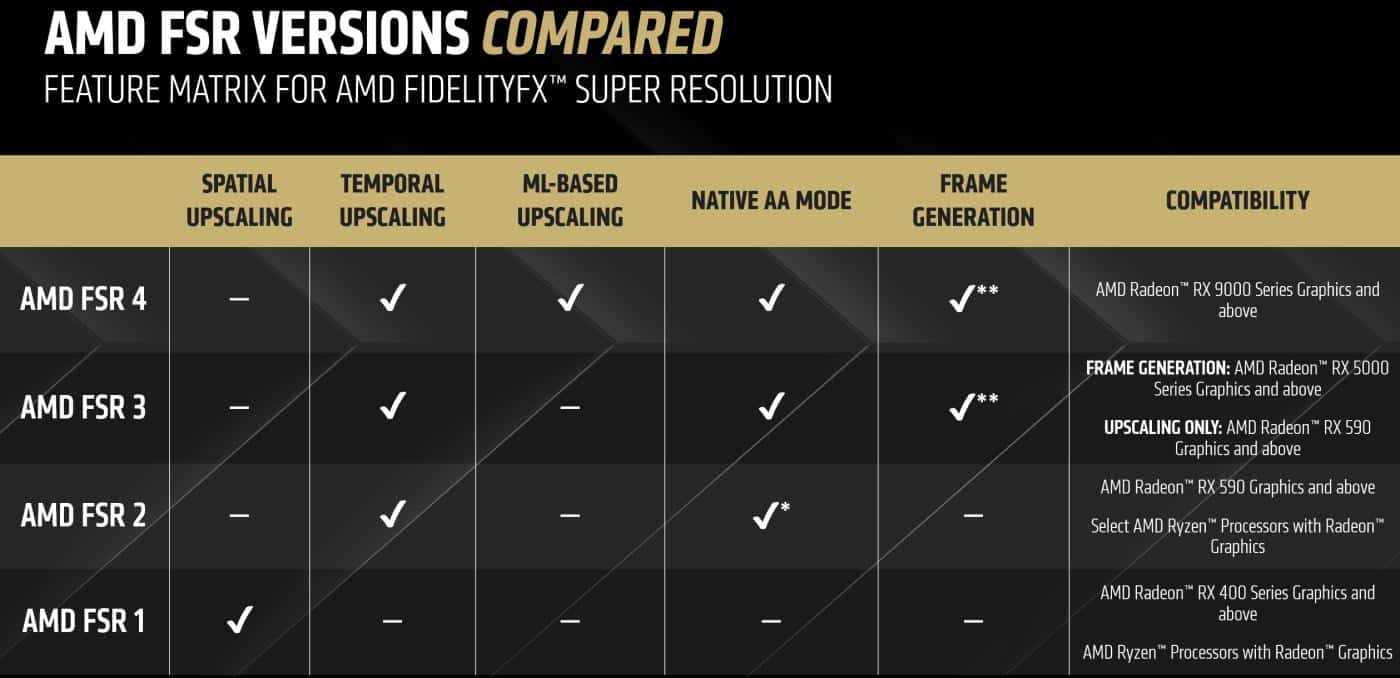
Let’s start with the bad news: FSR 4 will be exclusive for RX 9070 graphics cards only. This is because FSR 4 utilizes the new FP8 Wave Matrix Multiply Accumulate (WMMA) feature of RDNA 4, and the RX 9070 GPUs are the only ones that support it. AMD has stated in the past that it would attempt to make FSR 4 work on the previous generation AMD GPUs, but we haven’t heard back so far. Don’t lose hope; you never know what the future could bring.

If you have an RX 9070 GPU, you can easily upgrade supported FSR 3.1 games to FSR 4. When enabled in supported games with the AMD Software: Adrenalin Edition upgrade feature, AMD FSR 4 can be combined with existing in-game AMD FSR 3.1 advanced frame generation and Anti-Lag 2 for smoother and more responsive gaming with higher FPS.
AI-upscaling works pretty well, and with frame generation, you have increased frames, although most gamers don’t like the frame generation (FG) idea, especially the multiple frame generation (MFG) concept. So far, there is no word for RDNA 4 supporting MFG, and given the gamer’s reaction to Nvidia’s MFG, AMD shouldn’t rush to offer such an option.
 |
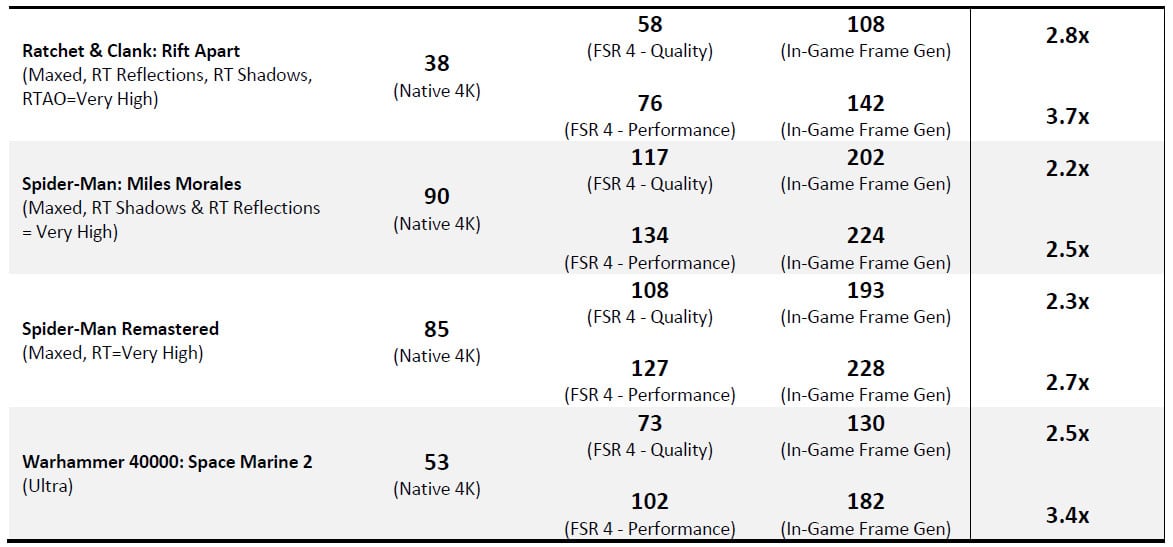 |
Data provided by AMD. Gaming data was measured on AMD Ryzen 7 9800X3D with AMD Smart Access Memory and Resizable BAR enabled.
AMD HYPR-RX with AMD Fluid Motion Frames
AMD Fluid Motion Frames (AFMF) is an in-driver frame generation technology designed to increase frame rates and gameplay smoothness. The new AFMF 2.1 update enhances visual quality, reducing ghosting effects and other artifacts. AFMF is part of the HYPR-RX profile, which can be enabled with a single click on the AMD Software home tab. HYPR-RX delivers the combined performance benefits of AFMF, Radeon Super Resolution, Radeon Anti-Lag, and Radeon Boost, delivering gamers the ultimate gaming experience.
- Prologue & Technical specifications
- Ray Tracing Explained
- RDNA 4 Explained
- Box & Contents
- Part Analysis
- Specifications Comparison
- Test System
- Game Benchmark Details
- Raster Performance
- RT Performance
- RT Performance + DLSS/FSR Balanced
- Raytracing Performance + DLSS/FSR Balanced + FG
- DLSS/FSR Balanced (No RT)
- DLSS/FSR Balanced + FG (No RT)
- Relative Perf & Perf Per Watt (Raster)
- Relative Perf & Perf Per Watt (Raster + DLSS/FSR)
- Relative Perf & Perf Per Watt (RT)
- Relative Perf & Perf Per Watt (RT + DLSS/FSR)
- Relative Perf & Perf Per Watt (RT + DLSS/FSR + FG)
- Rendering Performance
- Operating Temperatures
- Operating Noise & Frequency Analysis
- Power Consumption
- Clock Speeds & Overclocking
- Cooling Performance
- Epilogue

